



特別寄稿
D-STARの自動応答局の『中の人』をAIにやってもらおう!
2024年10月1日掲載

AIが『中の人』を務める自動応答局のイメージ
AI技術を活用して、D-STARの自動応答局を構築しました。従来の自動応答システムとは異なり、AIがリアルタイムで交信相手の状況や文脈を判断し、より自然かつスムーズな応答を実現します。本記事では、このシステムの仕組みや実装プロセス、実際の使用例を紹介し、アマチュア無線の新たな可能性を探ります。
自動応答局の動作の様子は、以下の動画をご参照ください。
動画1 動画2 動画3
D-STARの自動応答局とは
D-STAR(Digital Smart Technologies for Amateur Radio)は、JARL(日本アマチュア無線連盟)が開発したデジタル通信方式を利用するアマチュア無線のシステムです。D-STARは、デジタル通信方式を利用して遠距離の無線局とも交信できる特徴があり、インターネット経由で世界中の局と通信することが可能です。
自動応答局は、他の局からの呼び出しを受信した際、その局に対して自動的にメッセージを応答するものです。アイコムならやまハムクラブのJK3ZNB Fが有名です。
自動応答局を構成する
D-STARの自動応答局(Auto Reply Station)を構成するには、以下のステップに従います。
1. 必要な機器とソフトウェアの準備
- ・ D-STAR対応無線機: D-STARに対応した無線機が必要です。この記事では無線機単体でターミナルモードに対応しているIC-9700またはIC-705を使用します。
- ・ コンピューターとソフトウェア: 自動応答機能を制御するためのコンピューターとソフトウェアが必要です。この記事ではWindows10とPython3を使用します。
- ・ インターネット接続: D-STARネットワークとAPIサーバーに接続するためにインターネット接続が必要です。また、ターミナルモードを使用するには、IPv4と40000番のポート開放が必要です。詳しくは、2020年6月掲載のテクニカルコーナー「IC-705でターミナルモードを楽しむ」の記事をご参照ください。
今回構築したD-STAR AI自動応答局の構成図を図1に示します。
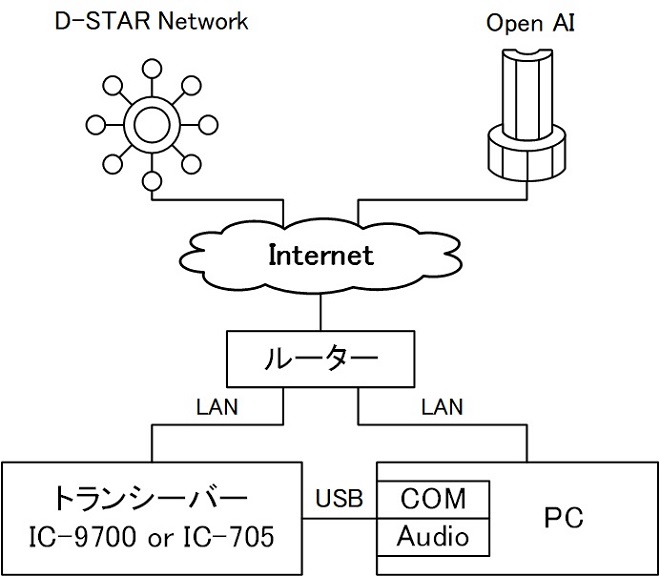
図1 D-STAR AI自動応答局の構成図
2. 無線機の設定
無線機には以下の設定が必要です。
- ・ [MENU]→[DV GW]を選択し、無線機をターミナルモードにします(図2)。ターミナルモードで自動応答局を運用することで、レピーターの専有や自動送信による妨害を防ぎます。

図2 無線機をターミナルモードにする
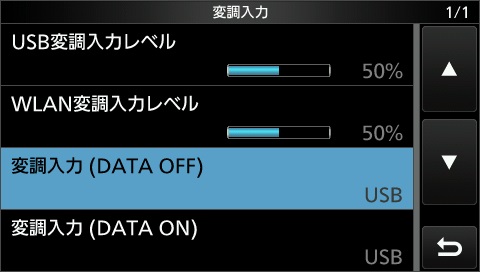
図3 変調入力の設定
この設定はCI-Vコマンドでも可能ですが、ユーザーが設定を元に戻す方法を理解できるように、あえて手動で設定する方法を選択しています。
3. コールサインの登録
D-STARを使うためには、JARL管理サーバーにコールサインを登録する必要があります。D-STARのWebサイトからユーザー登録をしてください。ここで登録されたコールサインがD-STARネットワーク上での識別子として使用されます。
プログラムの実行環境について
プログラムの開発には、Windows 10 Pro 64bit 22H2、Python 3.9.13を使用しました。プログラム内で PyAudio, PySerial, Pydub, OpenAIなどのライブラリを使用しますので、実行する環境で不足しているものはpipを使用して適宜インストールします。また、オーディオの処理にffmpegが必要ですので、インストールしてそのbinフォルダにPATHを通します。
AI関連のAPIの利用には、若干の費用とOpenAI社のAPI Keyが必要です。OpenAIのアカウントを開設し、トークンをチャージしてAPI Keyを入手しておきます。API Keyは環境変数[OPENAI_API_KEY]に登録します。
実行環境の構築に関する詳細手順については、2024年7月1日掲載の「AIによる音声認識で交信内容をテキスト化しよう!」の記事をご覧ください。
ファイル構成
プログラムは以下の3つのファイルで構成されています。
- ・ dstar_auto_ai_replyer.py
- 自動応答局本体プログラムです。全体のフローと音声録音を制御します。
- ・ dsar_comm.py
- 無線機制御プログラムです。コマンドの解析も行います。
- ・ openai_function.py
OpenAI 社のAPIアクセスプログラムです。API経由で「文字起こし」「チャット」「音声合成」を行います。
dstar_comm.pyとopenai_function.pyは、dstar_auto_ai_replyer.pyから呼び出されます。また、図4のように、本体プログラムと同じフォルダにユーザー環境設定ファイルsettings.jsonとdataフォルダを配置します。
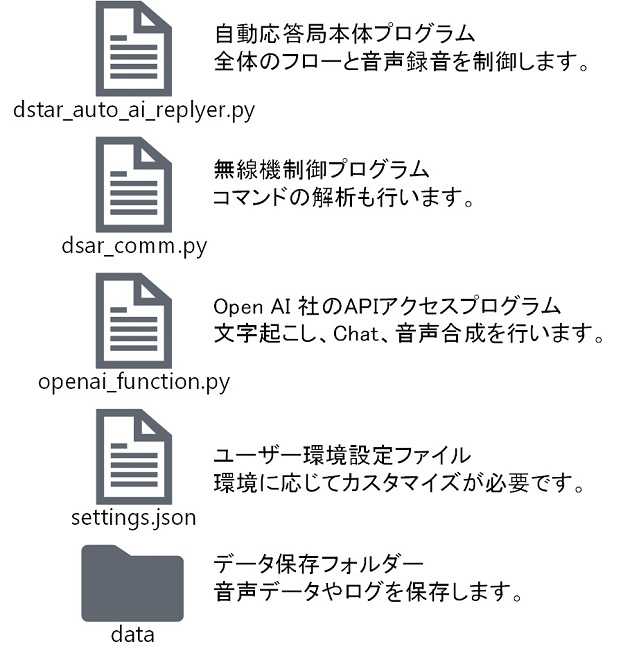
図4 プログラムのファイル構成
settings.jsonで以下の項目を設定します。
- ・ "max_rec_sec" ・・・ 録音の最大時間(秒)を設定します。 例: 300.0
- ・ "min_rec_sec" ・・・ 録音の最小時間(秒)を設定します。 例: 0.3
- ・ "input_device_idx" ・・・ 録音するデバイスのインデックス番号を指定します。 例: 1
- ・ "comport" ・・・ 無線機のCOMポートを指定します。 例: "COM12"
- ・ "civ_addr" ・・・ 無線機のCI-Vアドレスを指定します。 例: "a4"
- ・ "callsign_pronuc" ・・・ 自局のコールサインの読み方を指定します。 例: "ジェイ エム ワン ゼット エル ケー"
- ・ "my_callsign" ・・・ 無線機に指定するMY CALLSIGNを指定します。 例: "JM1ZLK F"
- ・ "rpt1_callsign" ・・・ 無線機に指定するRPT1 CALLSIGNを指定します。 例: "JM1ZLK Z"
- ・ "rpt2_callsign" ・・・ 無線機に指定するRPT2 CALLSIGNを指定します。 例: "JM1ZLK G"
"input_device_idx"は録音デバイスの番号です。PC環境により異なりますので、look_for_audio_input.pyで調べます。調べる方法は、「AIによる音声認識で交信内容をテキスト化しよう!」の記事で説明しています。
"comport"はCOMポートの番号です。PC環境により異なりますので、デバイスマネージャー等で調べます。詳しくは、USBドライバーインストールガイド(IC-9700, IC-705)をご参照ください。
"callsign_pronuc"は、自局のコールサインの読み方を指定する項目です。例えば、7M4MONを『ナナ エム ヨン モン』のように読んでしまう場合があるため、その発音を指定します。
自動応答局プログラムについて
作成した自動応答局のプログラムのフローチャートを図5に示します。
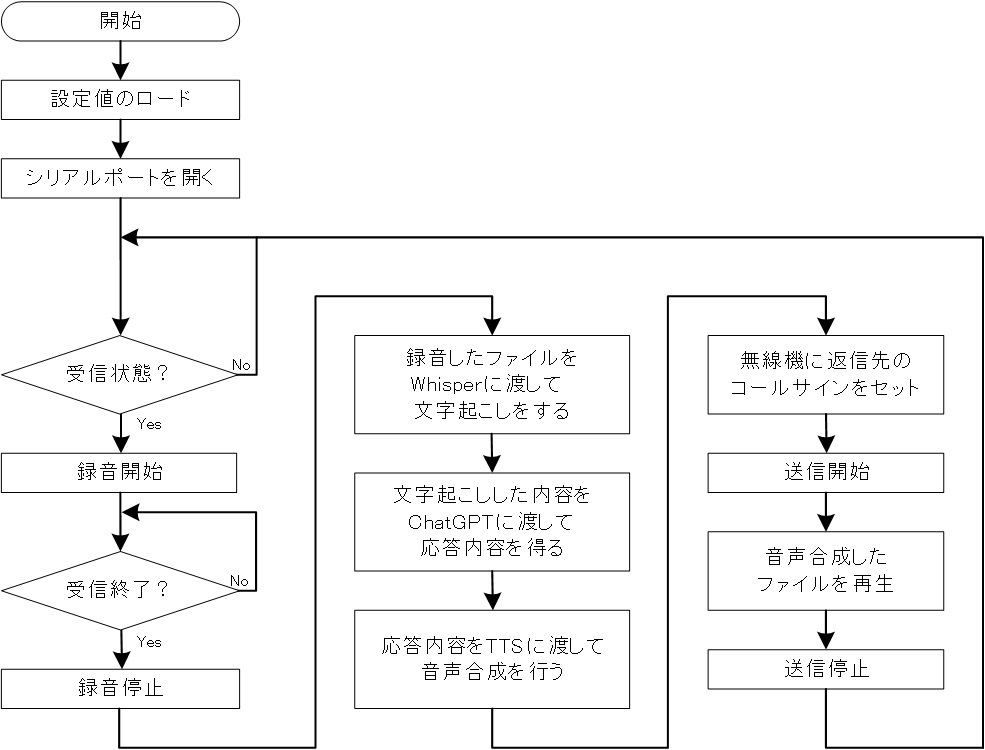
- 1. プログラムを開始したら設定値をロードして無線機のシリアルポートを開き、待受状態に移行します。
- 2. 無線機が音声信号を受信したら、録音を開始します。
- 3. 受信が終了したら、録音を停止してファイルに保存します。
- 4. 保存した録音ファイルをWhisper APIに渡して、文字起こしを実行します。
- 5. 受信音声の内容のテキストを得たら、それをChatGPTに渡して応答内容を得ます。
- 6. 得られた応答内容にコールサイン等をつけて、TTS(Text to Speech) APIに渡し、音声合成を行います。結果をstreamで得たらそれをmp3形式で保存します。
- 7. 無線機から直前に受信したコールサイン取得し、宛先にセットします。
- 8. 無線機を送信状態にします。
- 9. 6で保存した音声ファイルを再生します。
- 10. 再生が終了したら無線機の送信を停止し、待受状態に戻ります。
1~4については「AIによる音声認識で交信内容をテキスト化しよう!」の記事を、5については「生成AIを相手にしてCWの交信練習をしてみよう!」の記事をご参照ください。
なお、5のChatGPTに対するシステムプロンプトは["あなたは"+ mycallsign +"というアマチュア無線局です。アマチュア無線の交信相手として140字以内で応答しなさい。"]と指定しました。メッセージが長すぎると音声合成に時間がかかるため、140字以内に制限しました。
音声合成について
音声合成には、OpenAI社の‘tts-1’モデルを使用しました。‘tts-1’モデルはリアルタイムでの利用に最適化されており、今回のようなスピードが重要なアプリケーションに向いています。
声質は、"alloy", "echo", "fable", "onyx", "nova", "shimmer"の6つから選ぶことが出来ます。今回はランダムで声質を選択することにしました。使い方は、whisperやchatと同様で、clientを作成して、モデルと声質と合成する内容をAPIに渡します。しばらくすると、streamのresponseが返ってくるので、stream_to_fileでファイルに保存します。無線機を送信状態したらこのファイルを再生します。もし、無音が送信された場合は、再生先のデバイスが無線機のUSB Audioになっていることを確認してください。
無線機の制御について
「AIによる音声認識で交信内容をテキスト化しよう!」の記事では、シリアルポートのCTSとDSRを使って受信状態を判別していましたが、今回のアプリケーションでは、CI-Vコマンドを使用して無線機の状態取得と制御を行います。無線機には様々なコマンドが用意されていますが、今回使用するのは、'1C', '1F', '20' コマンドの3種類です。コマンド表を図6に示します。
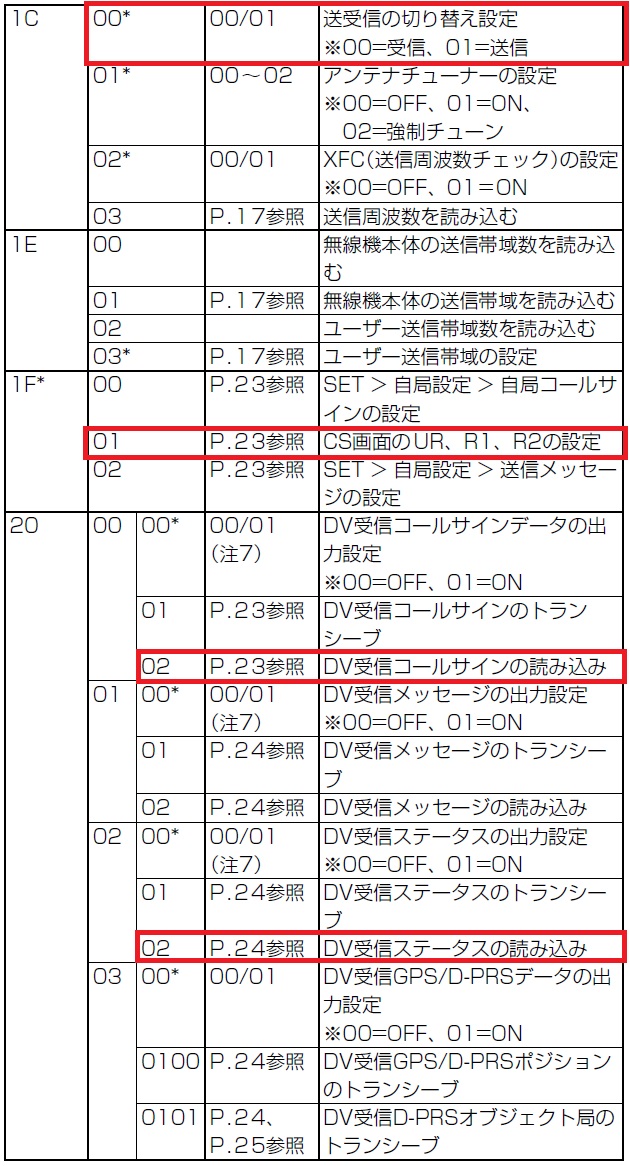
CI-Vコマンドのフォーマットやその他の詳細についてはIC-705の補足説明書(CI-Vコマンド説明)もしくはIC-9700の補足説明書をご参照ください。
なお、[CI-V USBエコーバック]の設定によってバイト配列上で目的のデータの位置が変わるため、正攻法でコマンドを解析してデータを取り出した方が良いでしょう。
・受信状態を取得する
「DV受信ステータスの読み込み」は[20 02 02]コマンドです。これを10ms間隔でポーリングして状態を取得します。DV受信ステータスデータの詳細を図7に示します。
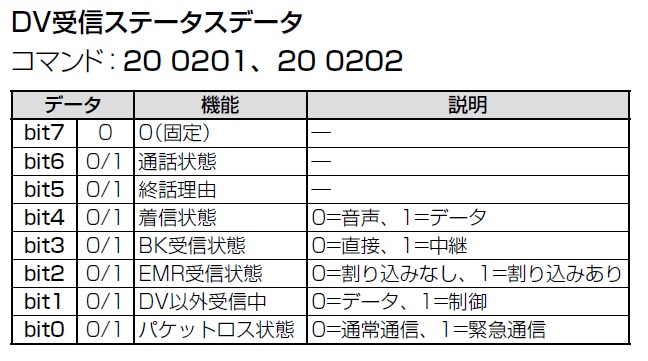
図7 DV受信ステータスデータの詳細
音声受信中はステータスが‘50'になります。よって、ステータスが‘50'になったら録音を開始し、他のステータスになったら録音を停止します。
・呼び出し元のコールサインを取得して宛先にセットする
自動応答局を構成するためには、呼び出し元のコールサインを宛先にセットする必要があります。「DV受信コールサインの読み込み」は[20 00 02]コマンドです。これを受信終了後に無線機に送信すると、CALLERのコールサインが含まれた、図8の応答を得ます。
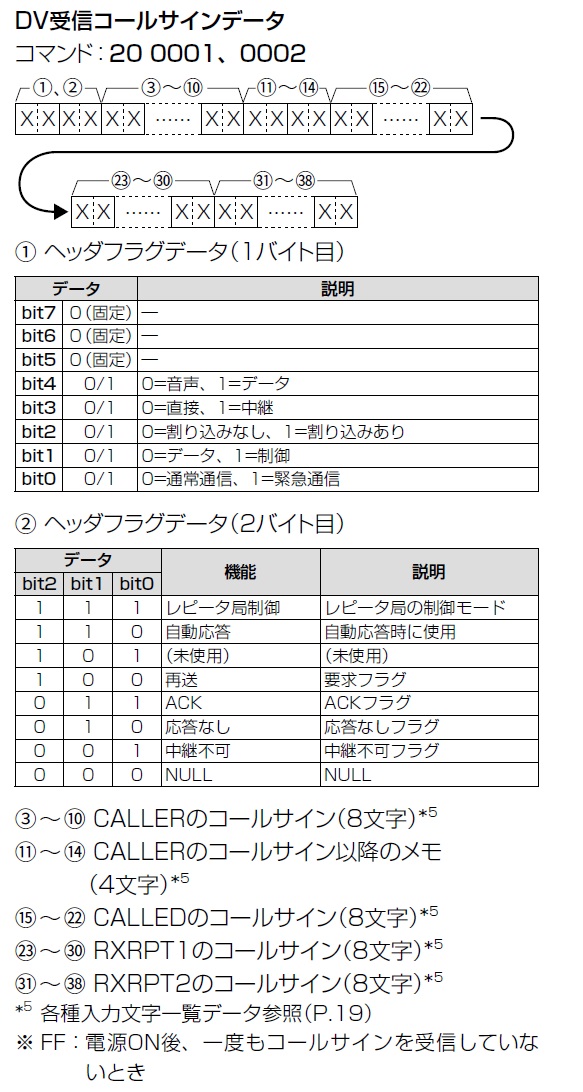
CALLERのコールサインは、3バイト目から10バイト目にありますので、その8文字を取り出します。
取り出したコールサインを宛先のコールサインにセットするには、[1F 01]コマンドを図9のとおりに使用します。

図9 DV送信コールサイン表示データの詳細
・無線機を送信状態にする
送受信の切り替え設定コマンドは、[1C 00]コマンドです。送信開始時に[01]をセットし、送信終了時に[00]をセットします。
自動応答局の運用について
今回構築した自動応答局「JM1ZLK F」をしばらく公開していますので、「JM1ZLK F」を呼び出してみてください。なお、ソースコードはGitHubに公開しています。機能追加や改善に関するプルリクエストはいつでも歓迎しています!
感想
AIを利用した自動応答システムを構築するプロジェクトに取り組み、多くの学びと新しい発見がありました。特に、AIの自然言語処理能力が想像以上に高く、交信の内容に応じて迅速かつ的確に返答できることに驚かされました。一方で、期待していた通りに機能しないケースや、予期せぬ応答をする場面もありました。狭帯域デジタル無線通信システムではボコーダー処理による音質の劣化は避けがたく、正しく文字起こしされないケースが散見されました。また、日本語は漢字変換や文法的な要素が複雑なので、誤変換や誤読によるミスコミュニケーションが発生しやすいようです。
OpenAI社が巨額の赤字を抱えながらも、ユーザーに極めて安価で革新的なサービスを提供してくれることに心から感謝しています。これからもAI技術がさらに発展し、より多くの人々の役に立つことを期待しています。
NEWS
連載記事
PHONEで楽しむQRP通信
第16回 東京都23区の低い場所からのQRP運用に挑戦!
Summits On The Air (SOTA)の楽しみ
その84 簡単SOTA運用地13
アパマンハムのムセンと車
第25回 モービル&アパマン運用に役立つヒント
新・エレクトロニクス工作室
第30回 LA1201テストボード
Masacoのうたのせかい
第五回 前へ進め
頭の体操 詰将棋
2024年10月の出題
特別寄稿
D-STARの自動応答局の『中の人』をAIにやってもらおう!
今月のハム
JI1UPL 平井玲緒さん
日本全国・移動運用記
第109回 秋田県全市町村移動
おきらくゴク楽自己くんれん
その42 暑さ対策万全の軽トラモバイルシャックでハムフェア
アマチュア無線の今と昔
第23回 浦島太郎になって迷っているカムバック組の皆様へ
今更聞けない無線と回路設計の話
【テーマ2】デシベルと無線工学 (第1話)
ぴよぴよラヂヲ@婦人部
第参拾五章 ハムフェア2024
JAIAコーナー






外部リンク
アマチュア無線関連機関/団体
各総合通信局/総合通信事務所
アマチュア無線機器メーカー(JAIA会員)
