



特別寄稿
AIによる音声認識で交信内容をテキスト化しよう!
2024年7月1日掲載
概要
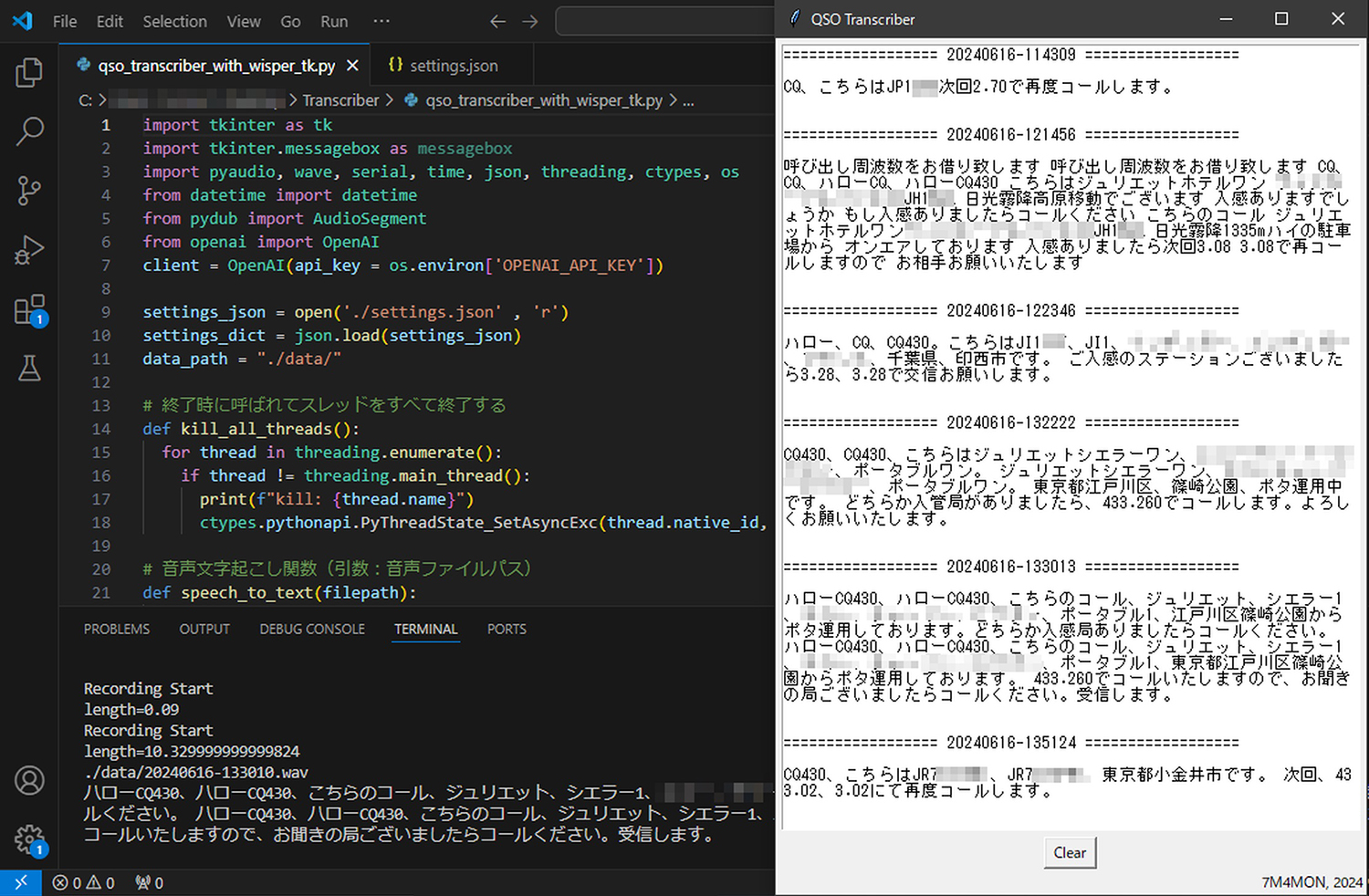
あのChat GPTで有名なOpen AI社が提供する文字起こしAPI[Whisper]を使用して、IC-9700で受信した交信内容をテキスト化します。ある日の430MHzの呼出周波数をワッチした実行画面を下図に示します。
接続について
IC-9700は背面にUSBポートを搭載していて、内部でAudio CODECに接続しています。そのため、オーディオ信号の取り込みはUSBケーブルを接続するだけで済みます。
交信内容を録音するには信号を受信しているか否かを検出する必要がありますが、IC-9700は背面のACCソケットのSQL S端子からスケルチ検出信号が出力されていますので、これを使用することにします。
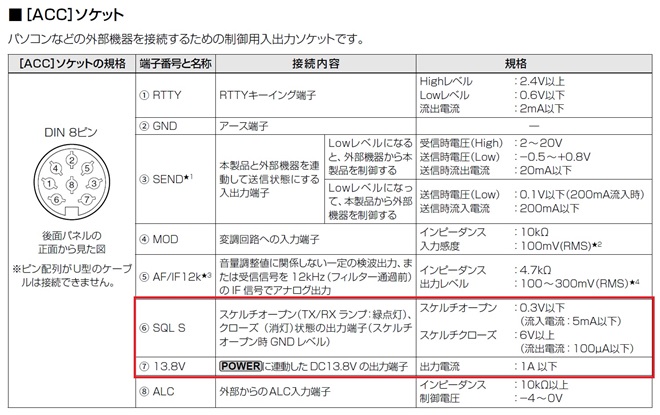
図2 IC-9700のACCソケットの説明図
SQL S端子の規格は、スケルチオープンで0.3V以下(流入電流5mA以下)、スケルチクローズで6V以上(流出電流100μA以下)です。ただし、IC-9700の電源をオフにするとSQL S端子はLになってしまうので、IC-9700の電源が入っていることもプログラムに知らせる必要があります。ACCソケットにはPOWERに連動した13.8V出力がありますので、これを使用します。
各状態のプログラムへの取り込みは、秋月電子のFT232RL USBシリアル変換モジュール[AE-UM232R]を使用しました。

図3 AE-UM232Rの販売ページ(秋月電子WEBサイトより)
今回の工作ではシリアル通信は使用せず、CTSとDSRを使用した単なる2ビットの入力としての用途です。製作したケーブルの回路図と外観写真を以下に示します。
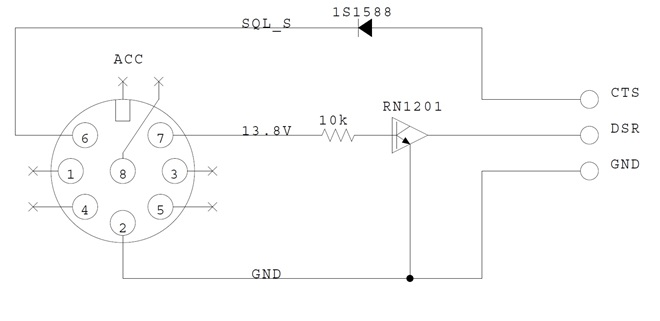
図4 信号検出ケーブルの回路図

写真1 信号検出ケーブルの外観写真
AE-UM232RのCTS/DSR端子はアクティブLで、非アクディブ時は5Vでプルアップされています。SQL S信号は非アクディブ時には6V以上でプルアップされていますので、ダイオード[1S1588]を挿入して、USBシリアル変換モジュールを保護します。
電源状態の検出にはバイアス抵抗内蔵のトランジスタ[RN1201]を使用しました。このトランジスタのエミッタ・ベース間の最大電圧は10Vなので、そのまま13.8Vに接続すると故障する恐れがあります。
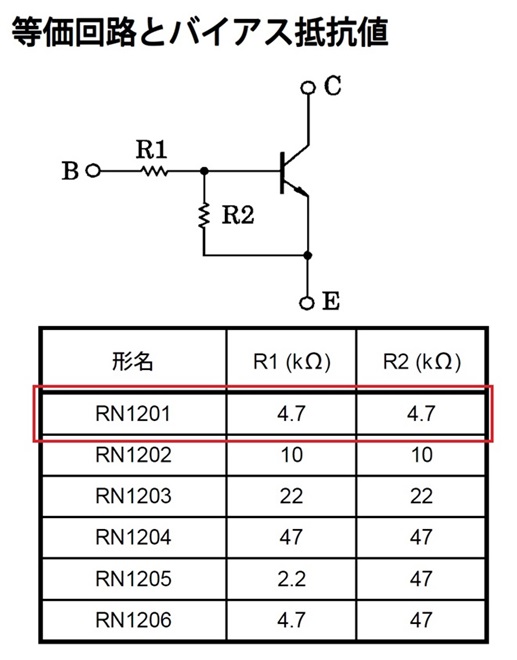
図5 RN1201の等価回路
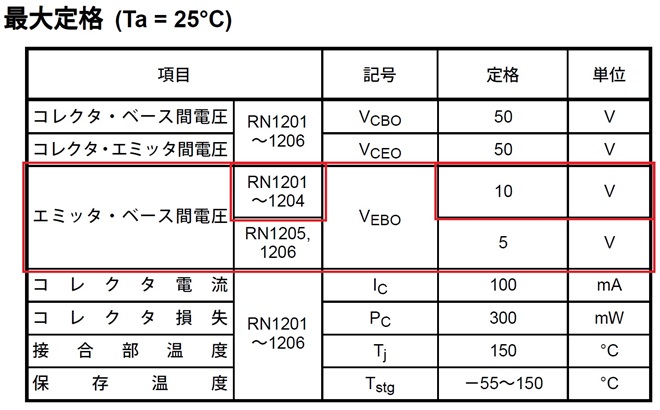
図6 RN1201の最大定格
そこで、ベースに直列に抵抗を挿入して内部のバイアス抵抗と分圧します。内部のバイアス抵抗はR1=R2=4.7kΩなので、ベースに10kΩを挿入しましたその結果、ベース端子は実測で4.5V程度となり定格内になりました。部品は写真2のようにDINコネクタのシェル内部に仕込みました。

写真2 ケーブルのシェル内部写真
Whisper APIについて
Whisper API はOpen AI社が提供する、AIを使用した文字起こしサービスです。利用料は1分1円以下と極めて安価ですが、有料です。そのため、Open AI社にアカウントを登録し、利用料をあらかじめクレジットカードからチャージしておく必要があります。
図7 Open AIの残額確認画面
また、APIの利用にはAPIキーが必要です。設定画面から申請して、あらかじめ入手しておきます。
図8 Open AIのAPIキー発行画面
APIキーを入手したら、PCの環境変数に追加します。Windowsの場合、「システムのプロパティ」を開き「詳細設定」タブの「環境変数」に[OPENAI_API_KEY]を追加します。これにより、プログラム内にキーを埋め込む必要がなくなり、意図しないキーの流出リスクを軽減することになります。
設定ファイルについて
プログラム実行前に以下の内容を設定する必要があります。プログラムと同じフォルダ内にJSON形式で[settings.json]という名前のファイルを保存します。キーと値の例を下表に示します。
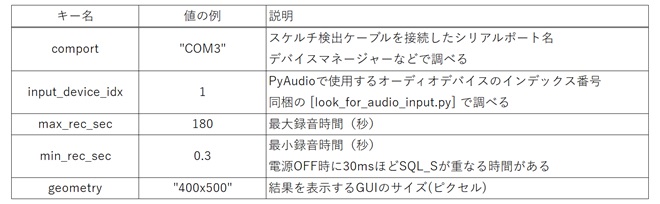
表1 settings.jsonのキーと値の例
このうち、input_device_indexは[look_for_audio_input.py]で調べます。このプログラムを実行すると接続されているオーディオデバイスの一覧を取得できます。実行結果の例を以下に示します。
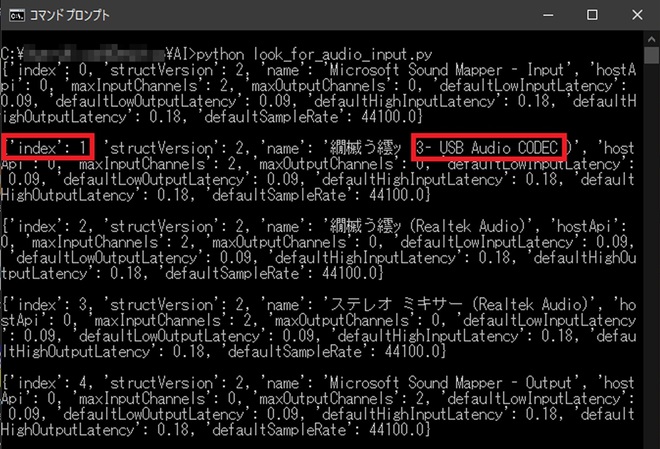
図9 look_for_audio_input.py実行例
IC-9700のUSB Audio CODECが‘index’ : 1に表示されましたので、この番号をinput_device_idxの値にセットします。
実行環境について
プログラムの開発には、Windows 10 Pro 64bit 22H2、Python 3.9.13を使用しました。プログラム内でjson, ctypes, pyaudio, wave, pyserial, pydubなどのライブラリを使用するので、実行する環境で不足しているものはpipを使用して適宜インストールします。openaiのライブラリは1.30.5を使用しました。0.28 以前のバージョンでは動作しませんのでご注意ください。
音声ファイルの転送量圧縮のためffmpegを使用しています。ffmpegをインストールし、インストールした先のbinフォルダを環境変数のPATHに追加します。
プログラムの流れ
プログラムの流れを以下に示します。

図10 プログラムのフローチャート
プログラムを開始すると、設定ファイルから各設定をロードし、シリアルポートを開きます。無線機が信号を受信してスケルチが開いたら録音を開始します。スケルチが閉じたら音声ファイルを保存して転送量削減のためmp3形式に圧縮します。圧縮した音声ファイルをWhisper APIに渡して文字起こしした結果を得ます。得られた結果をGUI上に表示すると同時にテキストファイルに保存します。なお、受信プログラムはTKのGUIとは別スレッドで処理しています。
プログラムはgithubに公開しています。
https://github.com/7m4mon/qso_transcriber/
まとめ
AIによる音声認識を使用することで、交信内容をある程度の精度でテキスト化することができました。キーワード検出によるアラート通知など、様々な用途に活用できるのではないでしょうか。
連載記事
SHFの世界
1200MHz帯での同軸ケーブルのロス測定
PHONEで楽しむQRP通信
第13回 小笠原JD1父島移動運用【後編・運用報告】
アパマンハムのムセンと車
第22回 モービル&アパマン運用に役立つヒント
Summits On The Air (SOTA)の楽しみ
その81 簡単SOTA運用地10
新・エレクトロニクス工作室
第27回 10dBアンプの実験
Masacoのうたのせかい
第二回 CDがあなたへ届くまでの月日♪
頭の体操 詰将棋
2024年7月の出題
特別寄稿
AIによる音声認識で交信内容をテキスト化しよう!
SHFの世界
和歌山-大阪間のSHF山岳回折通信実験
MasacoのFBチャレンジ!
六甲山から個人コールでHFハイバンドとSHFを中心に運用
日本全国・移動運用記
第106回 大型連休の北海道移動(後編)
おきらくゴク楽自己くんれん
その39 ALL JAコンテストに50MHzポケットダイポールVer.2で参戦
アマチュア無線の今と昔
第20回 浦島太郎になって迷っているカムバック組の皆様へ
今更聞けない無線と回路設計の話
【テーマ1】三角関数のかけ算と無線工学 (第28話)
ぴよぴよラヂヲ@婦人部
第参拾参章 ありがとう♡またね






外部リンク
アマチュア無線関連機関/団体
各総合通信局/総合通信事務所
アマチュア無線機器メーカー(JAIA会員)
